Die zentrale Aufgabe von Forwardern in einer Splunk-Infrastruktur ist es, Daten einzulesen und an die Indexer weiter zu leiten. In den meisten Fällen handelt es sich dabei um mehrere Indexer und nicht nur einen einzelnen Indexer. Um die eingelesenen Daten auf die verfügbaren Indexer zu verteilen, nutzen die Forwarder einen eingebauten und Splunk-spezifischen Load-Balancing-Mechanismus. In diesem Artikel wollen wir die verschiedenen Optionen des Load Balancing in Splunk betrachten und die passenden Einstellungen für verschiedenen Anwendungs-Szenarien diskutieren.
Warum ist die korrekte Konfiguration des Load Balancing wichtig?
Mit der Konfiguration des Load Balancing beeinflussen wir maßgeblich die Verteilung der eingelesenen Daten auf den Indexern. Die möglichst gleichmäßige Verteilung der Daten hat wesentliche Auswirkungen auf drei Aspekte:
- Verarbeitungszeit der Daten auf den Indexern: Wenn wir 1 GB Rohdaten auf 4 Indexer gleichmäßig verteilen (jeder bekommt 250 MB), dann werden alle 4 Indexer in etwa gleich lange brauchen, um diese Daten zu verarbeiten. Bei einem Referenz-Indexer könnte das ca. 1 Minute dauern. Wenn wir hingegen die Daten sehr ungleichmäßig verteilen (Indexer A bekommt 700 MB, alle anderen 100 MB), dann braucht Indexer A schon fast 3 Minuten für die Verarbeitung der Daten, während sich die anderen 3 Indexer schon langweilen.
- Speicherauslastung auf den Indexern: Mit der ungleichen Verteilung der Daten kommt es auch zu einer möglicherweise extremen ungleichen Auslastung des Speicherplatzes auf den Indexern. Die lokalen Festplatten oder zugewiesenen Speicherbereiche in einem Netzwerkbasierten Storage werden nach einiger Zeit bei manchen Indexern schon fast vollständig ausgelastet, während andere Indexer vielleich noch 50% freie Kapazität haben. In der Folge müssen wir entweder früher als notwendig den Speicherplatz erweitern, oder auf den mehr belasteten Indexern werden ggf. Buckets früher gelöscht als auch anderen, weil größenbeschränkende Limits der Indexe und Volumes erreicht werden.
- Suchzeit auf den Indexern: Ein ähnliches Problem wie bei der Indexierung ungleich verteilter Daten tritt dann auch bei den Suchen auf. Der Search Head muss warten, bir er die Ergebnissen von allen Indexern erhalten hat, bevor er die Suche abschließen kann – der Search Head wartet also auf den langsamten Indexer. Während die Suche über gleichmnäßg verteilte Daten auf jedem Indexer in etwa gleich lange dauert (vielleicht 25 Sekunden) und die Suche damit nach 25 Sekunden fertig ist, braucht der Indexer mit hohem Datenanteil vielleicht 70 Sekunden, während die weniger ausgelasteten Indexer schon nach 10 Sekunden fertig sind. De gesamte Suchzeit ist also gleich, aber der Benutzer muss länger auf das kumulierte Ergebnis warten.
Wir sehen also, dass es ausreichend Gründe gibt, das Load Balancing auf den Splunk Forwardern möglichst gut einzustellen, um Performance- oder Speicher-Problemen vorzubeugen.
Load Balancing nach Zeit oder Volumen
Das Load Balancing auf einem Splunk-Forwarder können wir grundsätzlich nach zwei Kriterien einstellen:
- Zeit: In der outputs.conf des Forwarders definieren wir den Parameter autoLBFrequency (Standard: 30 Sekunden).
- Volumen: In der outputs.conf des Forwarders definieren wir den Parameter autoLBVolume (Standard: 0 Bytes, diese Option ist damit deaktiviert)
Der Forwarder wechselt zum nächsten der verfügbaren Indexer, sobald das erste Kriterium erreicht wird.
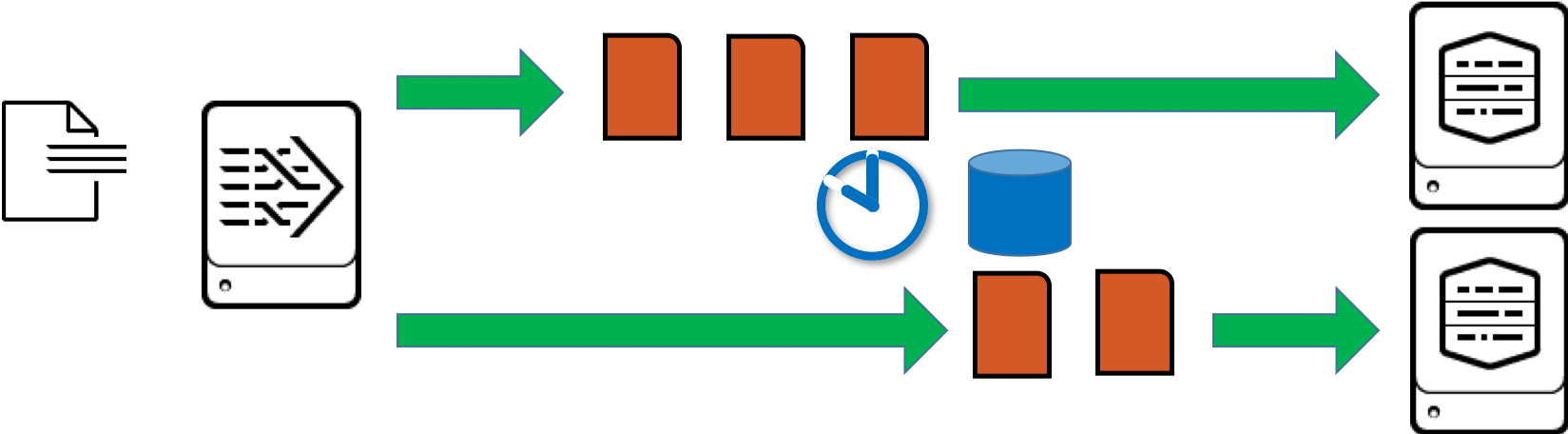
In der Standard-Einstellung sehen wir auf einem Forwarder also ein rein zeit-basiertes Load Balancing, bei dem nach ca. 30 Sekunden der Indexer gewechselt wird. Für diesen Wechsel verwendet der Forwarder das sogenannte Random Round Robin-Verfahren, bei dem der Forwarder die Indexer nicht immer in der gleichen Reihenfolge auswählt. Bei 4 verfügbaren Indexern kann dieser Wechsel z.B. so aussehen:
- Durchgang 1: 1,2,3,4
- Durchgang 2: 4,1,2,3
- Durchgang 3: 2,4,3,1
- Durchgang 4: 1,3,2,4
Load Balancing von geparsten und nicht geparsten Daten
Das Load Balancing für geparste oder nicht geparste Daten verhält sich bei Splunk unterschiedlich. Schauen wir uns zunächst die Arbeitsweise eines Heavy Forwarders an. Der erste Heavy Forwarder in einer Kette von Forwardern und Empfänger übernimmt in der Regel das Parsing der Daten, die er verarbeitet. Das bedeutet vor allem, dass er die Daten in einzelne Events aufteilt und dann eben auch Events an den nächsten Empfänger weiterleitet. Jedes einzelne Event trägt dabei neben dem ursprünglichen Inhalt der Log-Nachricht (_raw Event) auch die kompletten Meta-Informationen wie Source, Sourcetype, Host, Ziel-Index, Timestamp, Timezone etc.
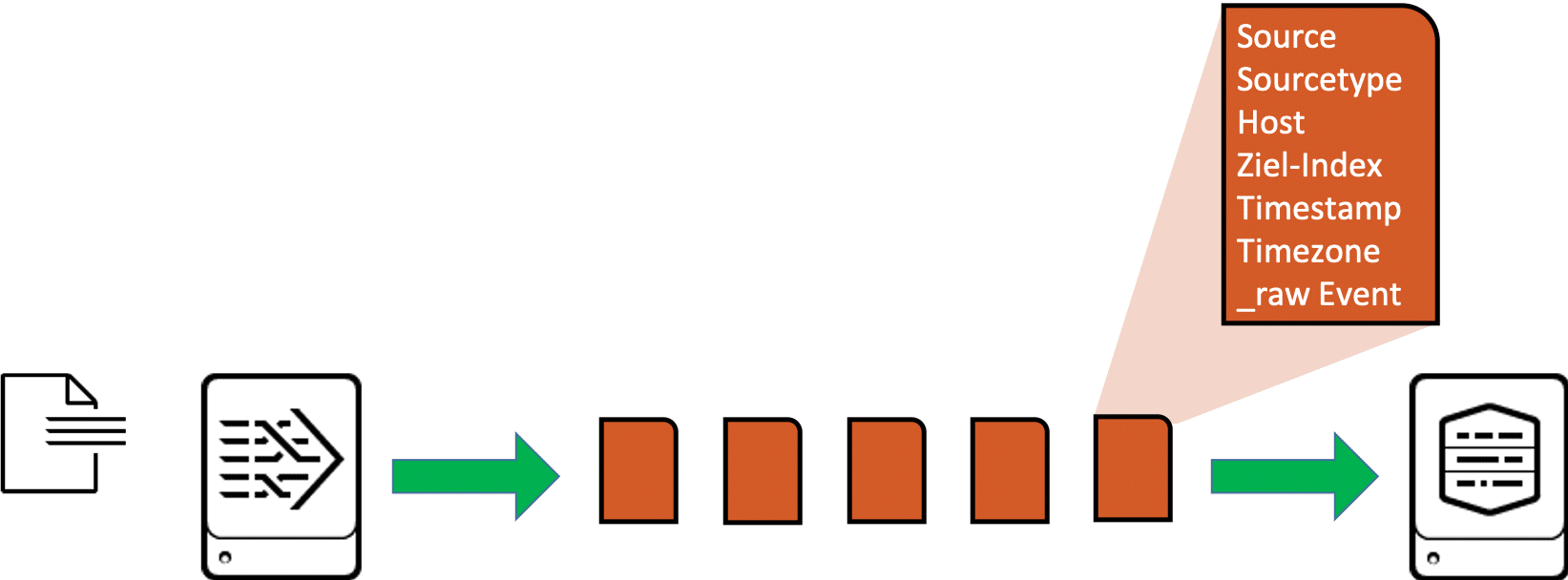
Der Heavy Forwarder kann daher sehr gut erkennen, wann es beim zeitbasierten Load Balancing „sicher“ ist, auf einen anderen Indexer zu wechseln, denn der HF kann zwischen zwei aufeinander folgenden Events umschalten, wenn das Intervall für das Load Balancing abgelaufen ist:

Bei einem Universal Forwarder verhält sich das Load Balancing grundsätzlich anders. In dem meisten Fällen erkennt der Universal Forwarder nicht die einzelnen Events, sondern er verarbeitet nur Blöcke von Daten. Diese Blöcke sind bei Datei-Inputs 64kB groß (bei TCP/UDP-Inputs 8kB). Für den gesamten Block werden die wichtigsten Meta-Informationen (Source, Sourcetype, Host, Ziel-Index) angefügt, in einem Block sind also auch nur Daten mit den gleichen Meta-Informationen enthalten. Da mehrere Events zusammen nicht unbedingt genau 64kB ergeben, kann am Ende eine 64kB-Blocks nur ein Teil eines Events liegen, am Anfang des nächsten 64kB-Blocks geht das Event dann weiter. Dieses Event wird also auf zwei aufeinander folgende Blöcke verteilt, in der Grafik sind diese Teil-Events in rot dargestellt:

Der Universal Forwarder kann beim Load Balancing also nicht einfach nach einem 64kB-Block auf den nächsten Indexer wechseln, weil dann ggf. der eine Teil eines Events auf den einen Indexer, der Rest des gleichen Events auf den nächsten Indexer übertragen wurde. Der Universal Forwarder muss also warten, bis der Datenstrom der diese 64kB-Blöcke mit gleichen Werten für Source, Sourcetype und Host unterbrochen wird. Das ist z.B. dann der Fall, wenn der UF eine End of File (EOF) in einer überwachten Datei erreicht, oder wenn ein Netzwerk-Input für eine gewisse Zeit keine Daten mehr empfängt:

Wir werden später auf dieses Verhalten zurückkommen.
Versuchsaufbau

In den folgenden Tests werden wir verschiedene Situationen des Load Balancing mit unterschiedlichen Daten-Inputs simulieren, dabei nutzen wir folgenden Versuchsaufbau:
- 1 Search Head, in diesem Beispiel CentOS 7 mit IP-Adresse 192.168.4.50. Auf dem Search Head konfigurieren wir die Suche auf den 4 Indexern in der distsearch.conf:
- 4 Indexer, CentOS 7 mit den IP-Adressen 192.168.4.51 bis 192.168.4.54. Auf den Indexern konfigurieren wir den Receiving Port 9997 in der inputs.conf:
- Zusätzlich rollen wir auf den Indexern die App
bri_lb_test_parsingaus, in welcher dieprops.conffür das richtige Parsing der Beispiel-Events enthalten ist. - 1 Universal Forwarder, in diesem Beispiel CentOS 7 mit IP-Adresse 192.168.4.55, auf dem wir die App
bri_lb_test_forwardingverwenden, in welcher dieinputs.confzum Überwachen der Test-Logs enthalten ist, dazu dieoutputs.confmit den verschiedenen Einstellungen für das Load Balancing und die Scripte zum Erzeugen der Test-Logs.
Test 1: Kontinuierlicher Daten-Input
Im ersten Test erzeugen wir mit dem Script lb_test_continousfile eine Log-Datei und schreiben kontinuierlich im Abstand von 0,1 Sekunde einen neuen Eintrag in diese Datei. Dazu nutzen wir folgenden Aufruf des Scriptes:
Das Script erzeugt 10.000 Einträge, läuft also ca. 15 Minuten und gibt uns so ausreichen Zeit, das Verhalten beim Load Balancing zu beobachten. Den Wechsel des Forwarders auf die verschiedenen Indexer können wir mit der folgenden Suche auf dem Search Head sichtbar machen:
Die Events, die wir so aufrufen, sehen in etwa so aus:
Wir sehen also, dass der Forwarder mehr oder weniger regelmäßig den Indexer wechselt, zu dem der Forwarder die Daten sendet. Das zeitliche Intervall beträgt meistens ca. 30 Sekunden, manchmal auch ca. 60 Sekunden. Vor allem ist die Reihenfolge nicht gleichmäßig, wir erkennen also das oben schon vorgestellte Random Round Robin-Verfahren.
Zusätzlich können wir auf der Kommandozeile des Forwarders die aktiven Verbindungen prüfen:
Wenn wir diesen Befehl nach einer Minute noch einmal ausführen, sehen wir z.B.:
Nachdem das Script alle 10.000 Einträge geschrieben hat, zeigt uns die folgende Suche die Verteilung der Events über die Indexer, wobei wir den Indexer im Feld „splunk_server“ wiederfinden:
Das Ergebnis sieht in etwa so aus:
Die Verteilung der Events über die Indexer ist also bei diesem sehr einfachen, kurzzeitigen Daten-Input nicht gleichmäßig, die Spanne reicht von 11% bis zu knapp 37%. In der Praxis können wir aber davon ausgehen, dass sich die Verteilung im Laufe der Zeit noch ausgleichen wird.
Test 2: Upload einer großen Datei
In manchen Anwendungsfällen können wir die Log-Dateien nicht kontinuierlich direkt nach dem Schreiben neuer Einträge mit einem Forwarder einlesen, sondern die Log-Informationen werden am Ort der Entstehung gesammelt, bevor diese nach einer gewissen Zeit in größeren Blöcken zur weiteren Verarbeitung bereitgestellt werden. Das kann z.B. dann sein, wenn in einem Netzwerk-Segment Log-Dateien gesammelt und in festen Intervallen (einmal pro Stunde oder einmal pro Tag) mit Hilfe einer Synchronisierung in ein anderes Netzwerk-Segment übertragen werden, wo diese dann mit einem Splunk Forwarder überwacht und eingelesen werden. Manche IT-Systeme sammeln die Log-Information auch intern, bis z.B. eine bestimmte Größe des Datenvolumens erreicht ist, und schreiben erst bei erreichen der entsprechenden Grenzwerte die Log-Informationen aus dem gekapselten System heraus in eine Log-Datei auf einem zugänglichen Speicherplatz. In beiden Fällen entstehen in gleichmäßigen oder wechselnden Intervallen größere Log-Dateien, die „plötzlich“ von einem Splunk Forwarder eingelesen werden.
Im zweiten Test wollen wir prüfen, wie sich solche größeren Dateien bzgl. des Load Balancing verhalten. Dazu erzeugen wir zunächst eine Log-Datei mit 500.000 Einträge an einem Speicherplatz, der nicht vom Forwarder überwacht wird:
:
Nachdem die Datei vollständig erzeugt ist, verschieben wir diese in ein vom Splunk Universal Forwarder überwachtes Verzeichnis:
Die für den test erzeugte Datei mit 500.000 Einträgen ist ca. 63 MB groß. Bei der Standardeinstellung des Universal Forwarder mit einem maximalen Datendurchsatz von 256KBps (maxKBps in limits.conf) dauert es also etwas mehr als 4 Minuten, diese Datei zu übertragen. Die Verteilung der Events aus der großen Datei über die Indexer können wir mit der folgenden Suche prüfen:
Wir können sehen, dass alle Events aus dieser Datei auf einem einzigen Indexer zu finden sind, und nicht wie gewünscht auf alle Indexer verteilt wurden.
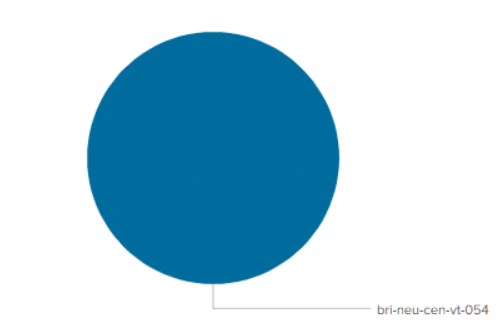
Das liegt am Verhalten des Universal Forwarders beim Load Balancing von nicht geparsten Daten – der Forwarder sendet alle Daten-Blöcke solange an den gleichen Indexer, bis er in der überwachten Datei ein EOF gefunden hat. Und das findet er in diesem Falle erst dann, wenn er die komplette große Datei eingelesen und verarbeitet hat.
Test 3: Aktivieren von ForceTimebasedAutoLB
Wie können den Universal Forwarder dazu bringen, den Indexer nach einer bestimmten Zeit zu wechseln, selbst wenn kein EOF erkannt wurde? Um dies zu Testen, setzen wir die Option forceTimebasedAutoLB = true in der outputs.conf des Forwarders:
Nachdem wir Splunk neugestartet haben, um die Änderungen in der outputs.conf aktiv zu machen, erzeugen wir uns erneut eine große Datei:
Sobald diese Datei fertig geschrieben ist, verschieben wir diese in das Upload-Verzeichnis:
Wenn wir uns jetzt die Verteilung der großen Datei auf den Indexern anzeigen lassen sehen wir, dass alle Server Einträge erhalten haben.
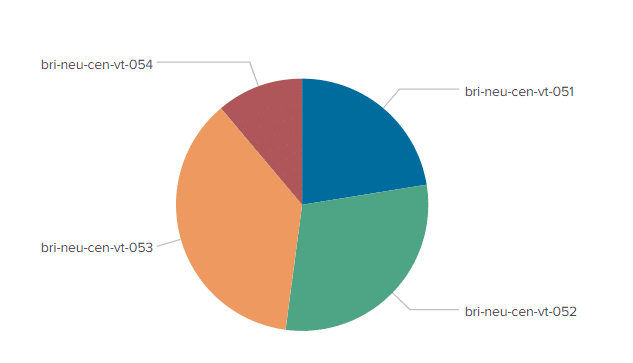
Wie kommt es nun, dass die Daten jetzt besser verteilt werden, obwohl doch weiterhin die Daten-Blöcke von 64kB gesendet werden?
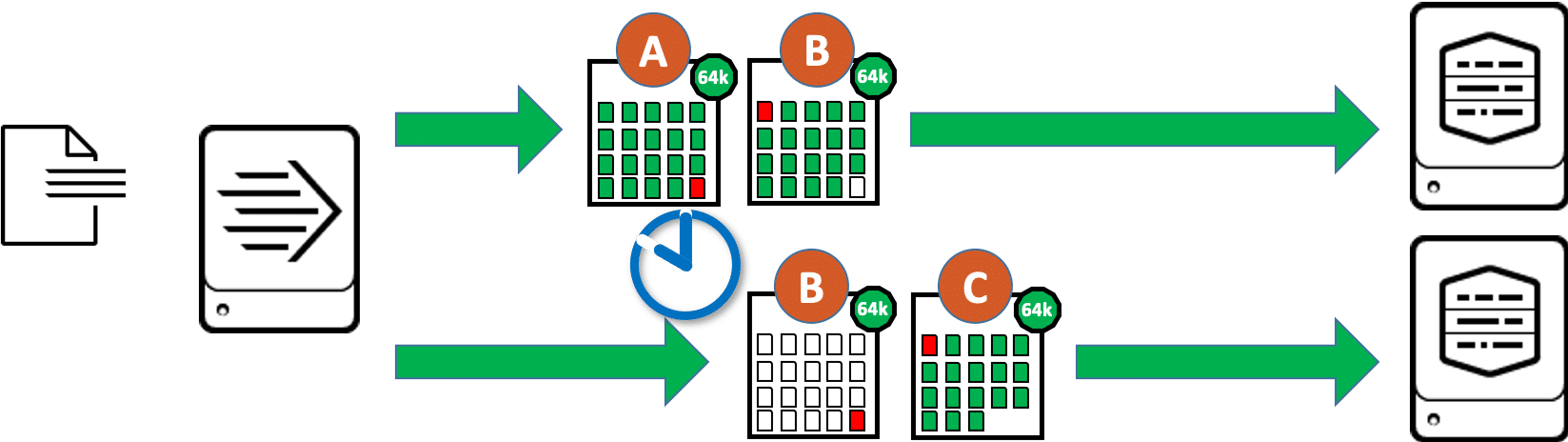
Der Forwarder schickt in diesem Fall den letzten Daten-Block vor dem Wechsel des Indexers zweimal ab, hier im Bild der Block (B):
- Die erste Kopie dieses Datenblocks geht an den bisher verbundenen Indexer, der Forwarder markiert diesen Daten-Block dabei explizit als den letzten Block einer Sequenz im forceTimebasedAutoLB-Modus. Der Indexer empfängt diesen Block, parst die Events und behält alle bis auf das letzte letzte, angefangene Event dieses Blocks. Diese Teil-Event wird verworfen.
- Die zweite Kopie dieses Datenblocks geht an den nächsten anderen Indexer, der Forwarder markiert diesen Daten-Block dabei explizit als den ersten Block einer Sequenz im forceTimebasedAutoLB-Modus. Der Indexer empfängt diesen Block, parst die Events und behält ausschließlich das letzte, angefangene Event dieses Blocks. Dieses Event wird dann im folgenden Block (C) fortgesetzt. Alle anderen Events aus Block (B) werden verworfen.
Durch das doppelte Senden eines 64kB-Daten-Blocks kann der Forwarder nun also den Indexer wechseln, auch wenn er noch kein EOF in der Datei erkannt hat.
Test 4: forceTimebasedAutoLB bei sehr langen Events
Aber was passiert, wenn ein Event größer als 64kb ist? In manchen Fällen kommt es vor, dass einzelne Events extrem lang werden. Beliebte Kandidaten dafür sind strukturierte Events im XML-Format, oder reine Text-Event, die große XML-Strukturen als Payload enthalten.
Für den nächsten Test erzeugen wir uns eine neue große Datei, die dieses mal sehr langen Events besteht. Hierfür nutzen wir das Skript lb_test_longevents.py mit dem unten folgenden Aufruf:
Danach verschieben wir die Datei mit den langen Events in das Upload-Verzeichnis:
Beim Betrachten der Verteilung der Events über die Indexer fällt nichts Negatives auf. Mit der folgenden Suche zeigen wir die entsprechenden Events an, und auch da sehen wir zunächst nichts Auffälliges, die Events sehen aus wie gewünscht, beginnen mit einem Zeitstempel und sehen auch sonst unauffällig aus:

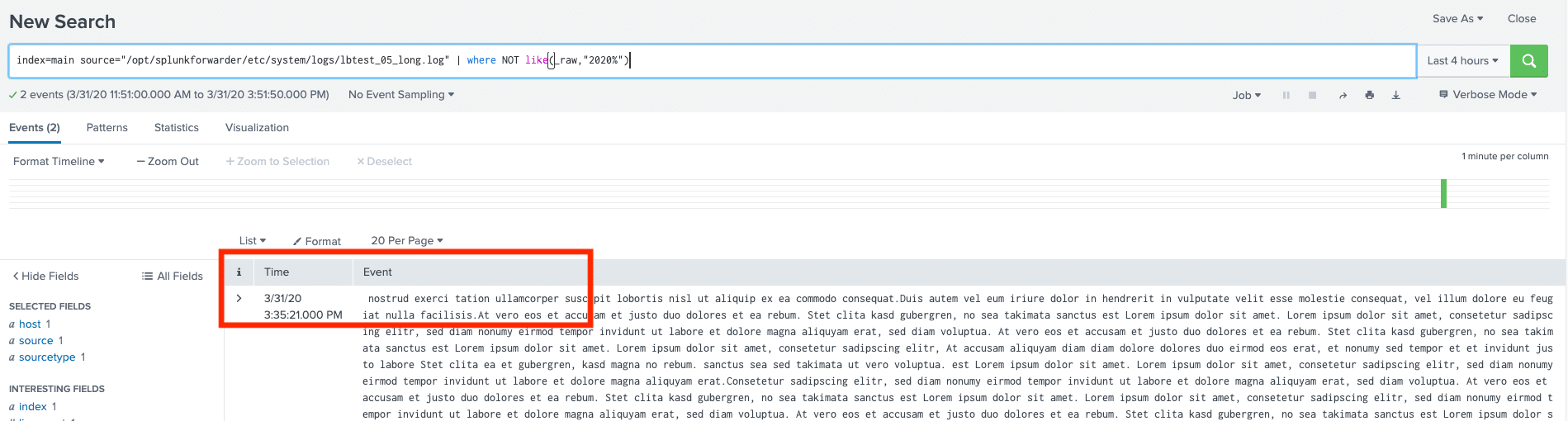
Dann erweitern wir die Suche und forschen gezielt nach Events, die eben nicht mit dem Zeitstempel beginnen:
Wir sehen nun, dass es einige wenige Events gibt, die „mitten drin“ anfangen und nicht mit einem Zeitstempel:
Warum sind die Events jetzt abgeschnitten, nur weil sie länger als 64kB sind? Wir haben oben gesehen, dass bei aktivierter Option forceTimebasedAutoLB = true der Forwarder einen Daten-Block beim Wechsel des Indexers zwei mal schickt, einmal an den bisherigen und einmal an den nächsten Indexer. Wenn die Events größer als die Daten-Blöcke sind, kann es sein, dass einzelne Events über 3 Daten-Blöcke verteilt werden. Und in ungünstigen Fällen liegt dieses lange Event (in der Grafik gelb dargestellt) gerade in dem Bereich, wo der Indexer gewechselt wird. Die Folge:
- Der erste Indexer erhält die Daten-Blöcke (A) und (B) und behält zunächst die vollständigen Events aus Block (A). Dazu findet er in Block (A) das angefangene lange, gelbe Event, welches in Block (B) fortgesetzt wird. Der erste Indexer empfängt aber nicht Daten-Block (C), in dem der Rest des langen. gelben Events zu finden wäre. Der erste Indexer speichert schließlich ein am Ende abgeschnittenes Event.
- Der zweite Indexer erhält die Daten-Blöcke (B) und (C). Aus Block (B) als Kopie der Übertragung an den vorherigen Indexers verwirft er er alles, was nicht nach dem Beginn eines Events aussieht. Da wir uns hier mitten im Event befinden, erkennt der Indexer keinen Zeitstempel, also keinen Beginn eines Events und verwirft schließlich alles aus diesem Daten-Block. Da Daten-Block (C) wieder ein „normaler“ und kein kopierter Daten-Block ist, wird dieser vollständig verarbeitet. Der Rest des langen, gelben Events wird also hier als separates Event verarbeitet, solange bis das nächste Event in diesem Daten-Block beginnt. Dieses Fragment eines Events verfügt vermutlich nicht über einen gültigen Zeitstempel, der Zeitstempel wird also anhand einer der Standard-Regeln von Splunk ermittelt. Sehr wahrscheinlich erbt das Events in diesem Fall den Zeitstempel des letzten Events mit dem gleichen Wert für Source.

Test 5: EVENT_BREAKER
Mit der Version 6.5 hat Splunk die Funktion des EVENT_BRREAKER eingeführt. Das ist schon ein paar Jahre her, dennoch kennen viele Anwender und Administratoren diese Option noch nicht. Mit konfiguriertem EVENT_BRREAKER kann auch ein Universal Forwarder die Grenzen zwischen den Events erkennen. Der UF wird nach wie vor die Daten nicht parsen, aber mit Kenntnis über die Event-Grenzen kann der UF beim Load Balancing den Wechsel auf den nächsten Indexer genau zwischen zwei Events auslösen. Das Festhalten des Forwarders an einem Indexer bei sehr großen Dateien, das doppelte Übertragen von Daten-Blöcken beim forceTimebasedAutoLB und die Problematik der überlangen Events entfallen damit komplett.
Zuerst deaktivieren wir das erzwungene, zeitbasierte Load Balancing in der outputs.conf des Forwarders mit forceTimebasedAutoLB = false.
Anschließend setzen wir in der props.conf auf dem UF für den gewählten Sourcetype den Parameter EVENT_BREAKER_ENABLE = true, um auf dem UF die Nutzung der Event-Grenzen zu aktivieren. Dazu teilen wir dem UF mit dem Parameter EVENT_BREAKER = ([\r\n]+) mit, wo die Grenzen zwischen den Events sind:
:
Wenn wir den vorherigen Test wiederholen stellen wir fest, dass nun alle Events vollständig und fehlerfrei übertragen und indexiert werden.
Fazit und Empfehlungen
In den durchgeführten Test-Szenarien haben wir gesehen, dass die Standard-Einstellung mit einem zeitbasierten Load Balancing von 30 Sekunden nur ein erster Vorschlag ist, um das Load Balancing überhaupt zu aktivieren. Allerdings ist diese Einstellung nur in den wenigsten Fällen auch tatsächlich die beste Option. Als „Best Practice“ für das Load Balancing kann man folgende Regeln verwenden:
- Line Breaking für jeden Sourcetype auf den Indexern (bzw. bei Intermediate Heavy Forwardern auf diesen IHF-Instanzen) in der
props.confvollständig konfigurieren mitLINE_BREAKER = <regulärer Ausdruck>undSHOULD_LINEMERGE = false - Auf den Universal Forwardern möglichst nah an der Datenquelle in der
props.confdie Nutzung der Event-Grenzen aktivieren und den regulären Ausdruck für diesen Sourcetype inEVENT_BREAKER = <regulärer Ausdruck>kopieren - Auf den Universal Forwardern in der
outputs.confden Parameter für die Frequenz des zeitbasierten Load Balancing auf einen höheren Wert als den Standard setzen, z.B.autoLBFrequency = 60. So vermeiden wir zu häufige Wechsel des Indexers, was ansonsten zu Problemen beim massenhaften Auf- und Abbau von TCP-Verbindungen zwischen Universal Forwardern und Indexern führen kann. - Auf den Universal Forwardern in der
outputs.confden Parameter für das volumenbasierte Load BalancingautoLBVolumeauf einen Wert setzen, der möglichst nah an die übertragene Datenmenge in dem eingestellten Intervall herankommt. Bei den standardmäßigen 256kBps sind das z.B. ca. 15 MB.
Mit diesen Einstellungen haben wir eine Basis für das Load Balancing, bei dem nicht übermäßig viele TCP-Verbindungen auf- und wieder abgebaut werden müssen, und dennoch erreichen wir eine recht gleichmäßige Verteilung der Daten / Events über die Indexer. Von dieser Basis ausgehend können wir dann die Werte z.B. für Forwarder mit deutlich höherem Datendurchsatz weiter optimieren.
Übrigens bieten wir auch Jobs an. Mehr erfährst du hier.